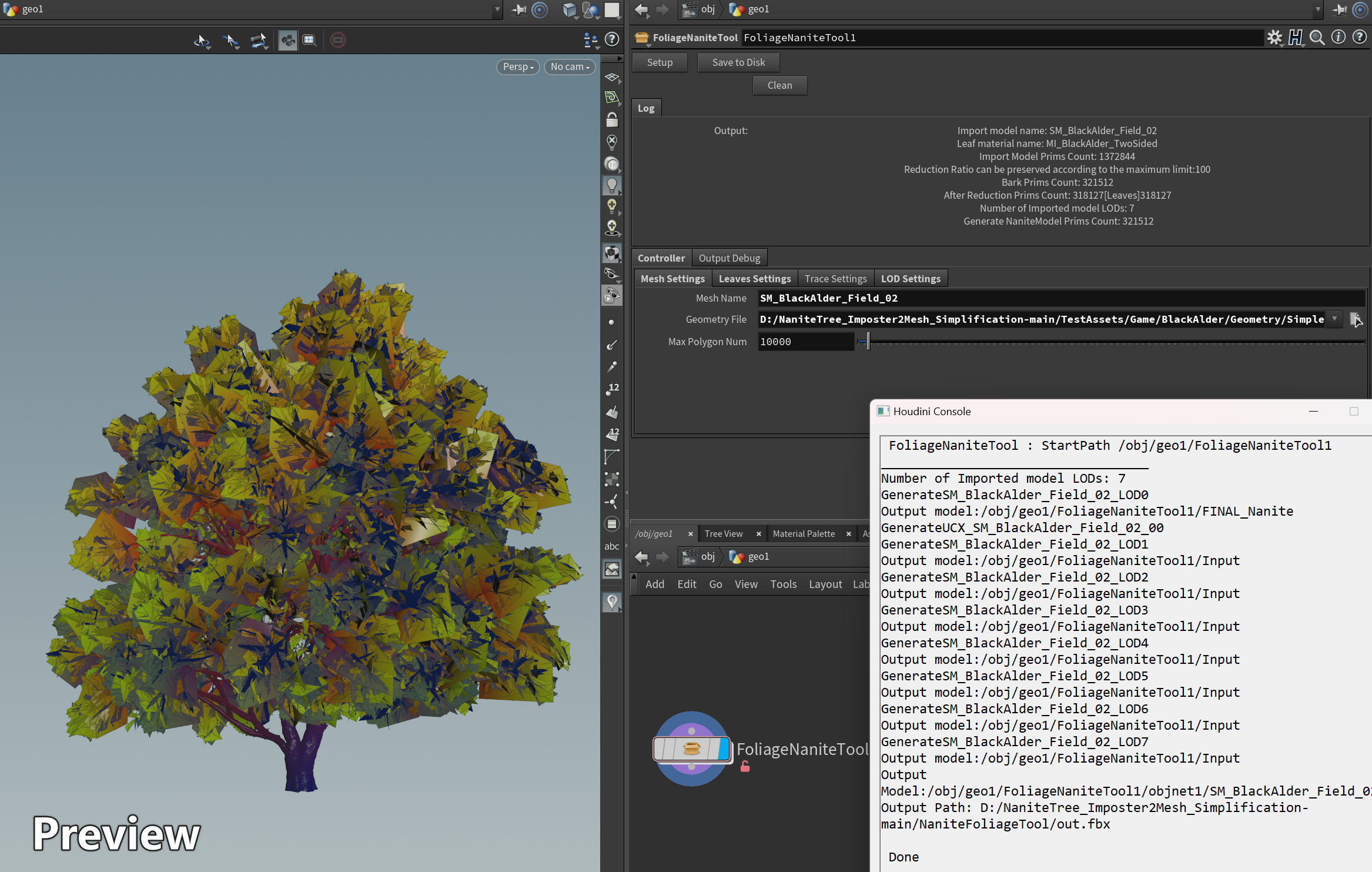
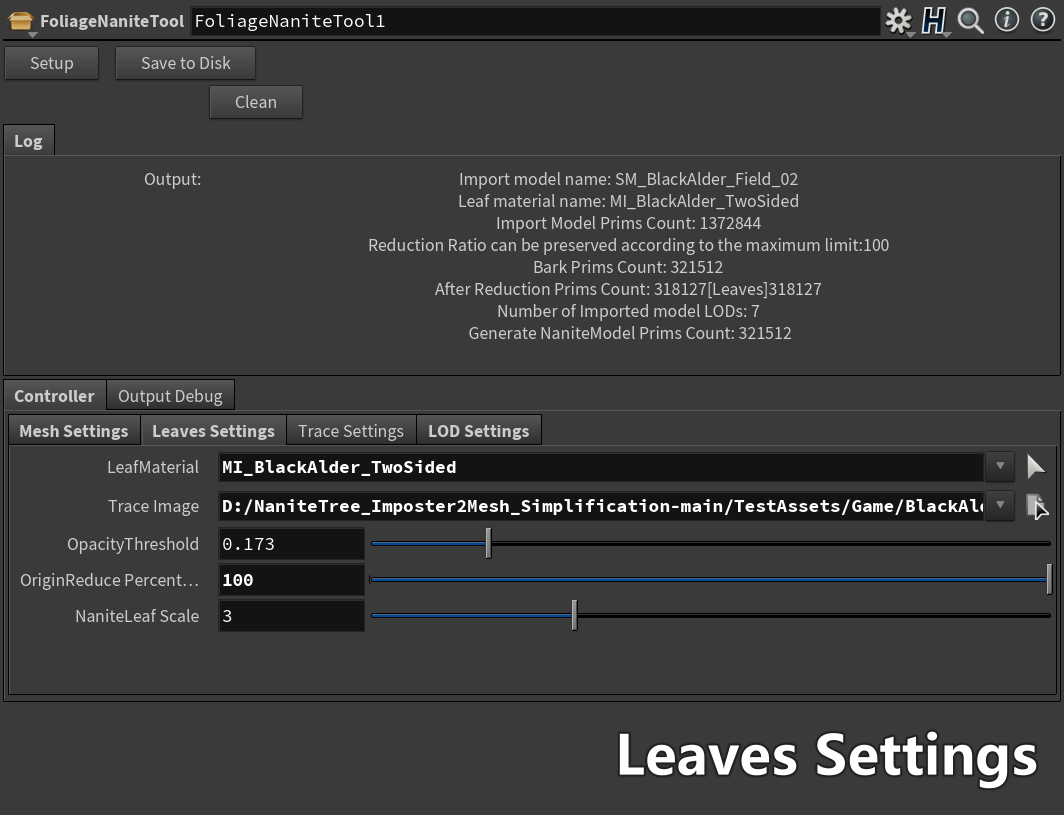
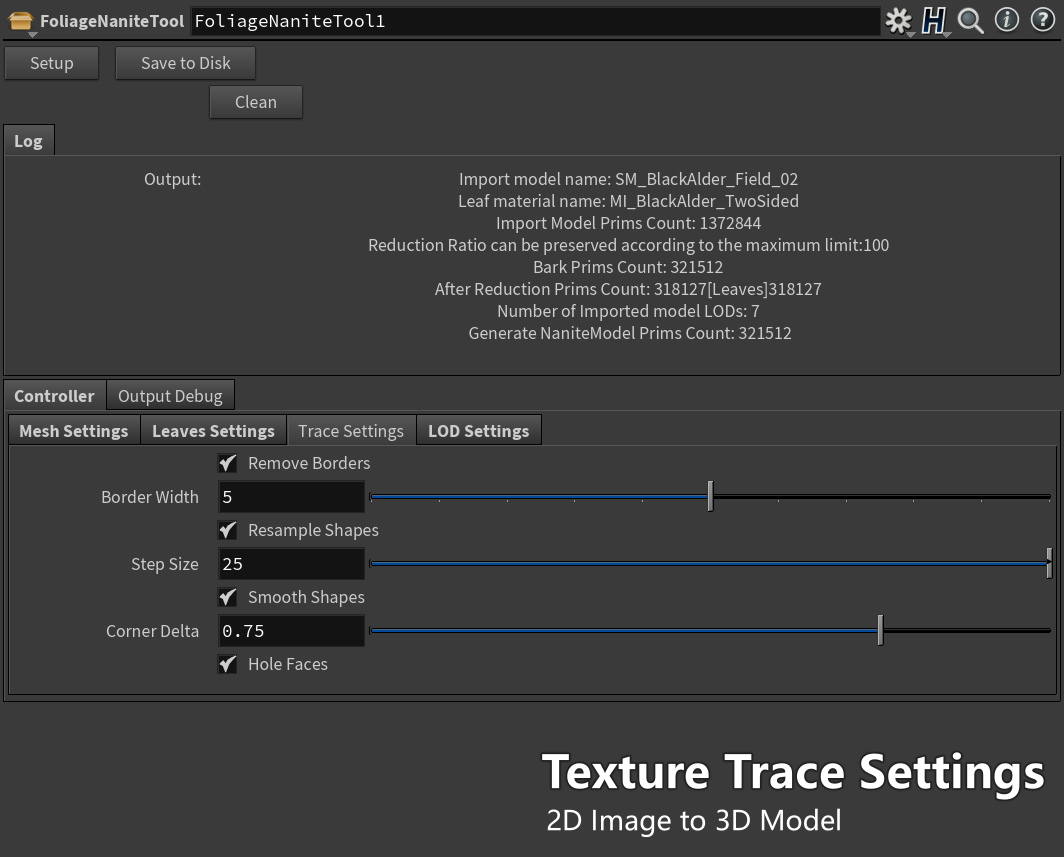
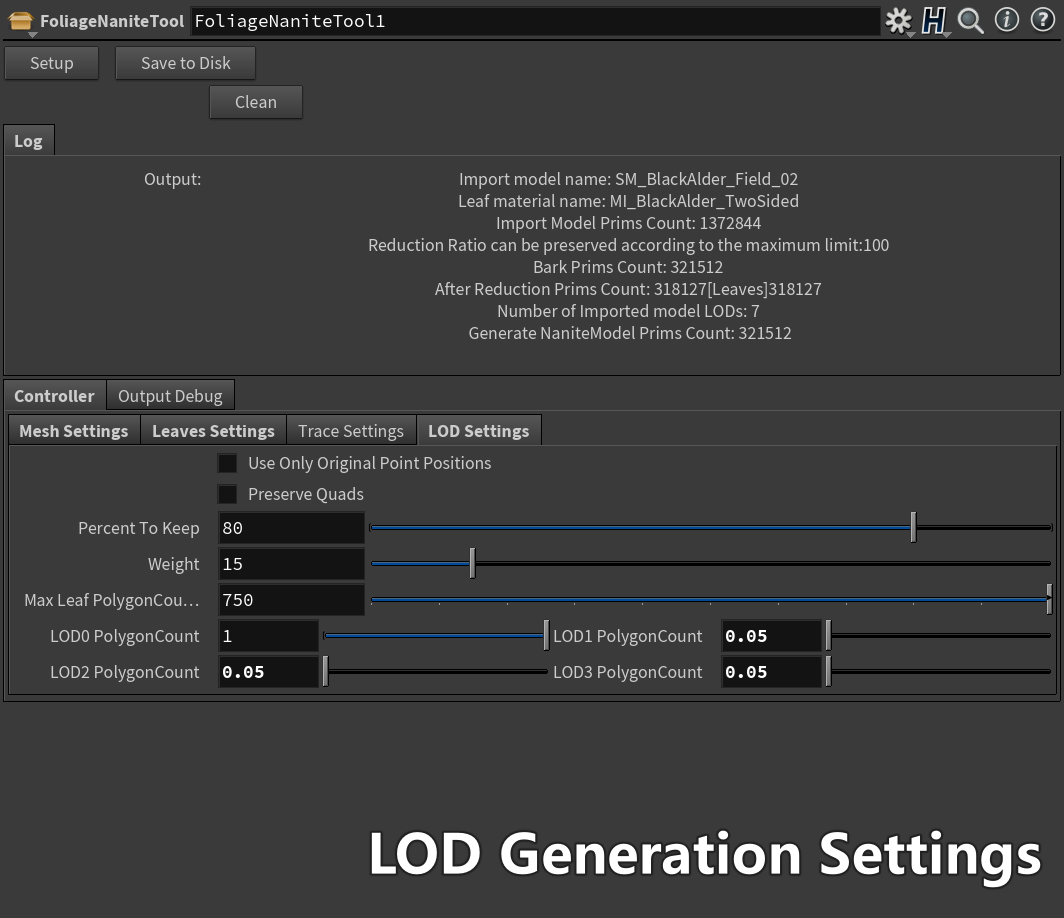
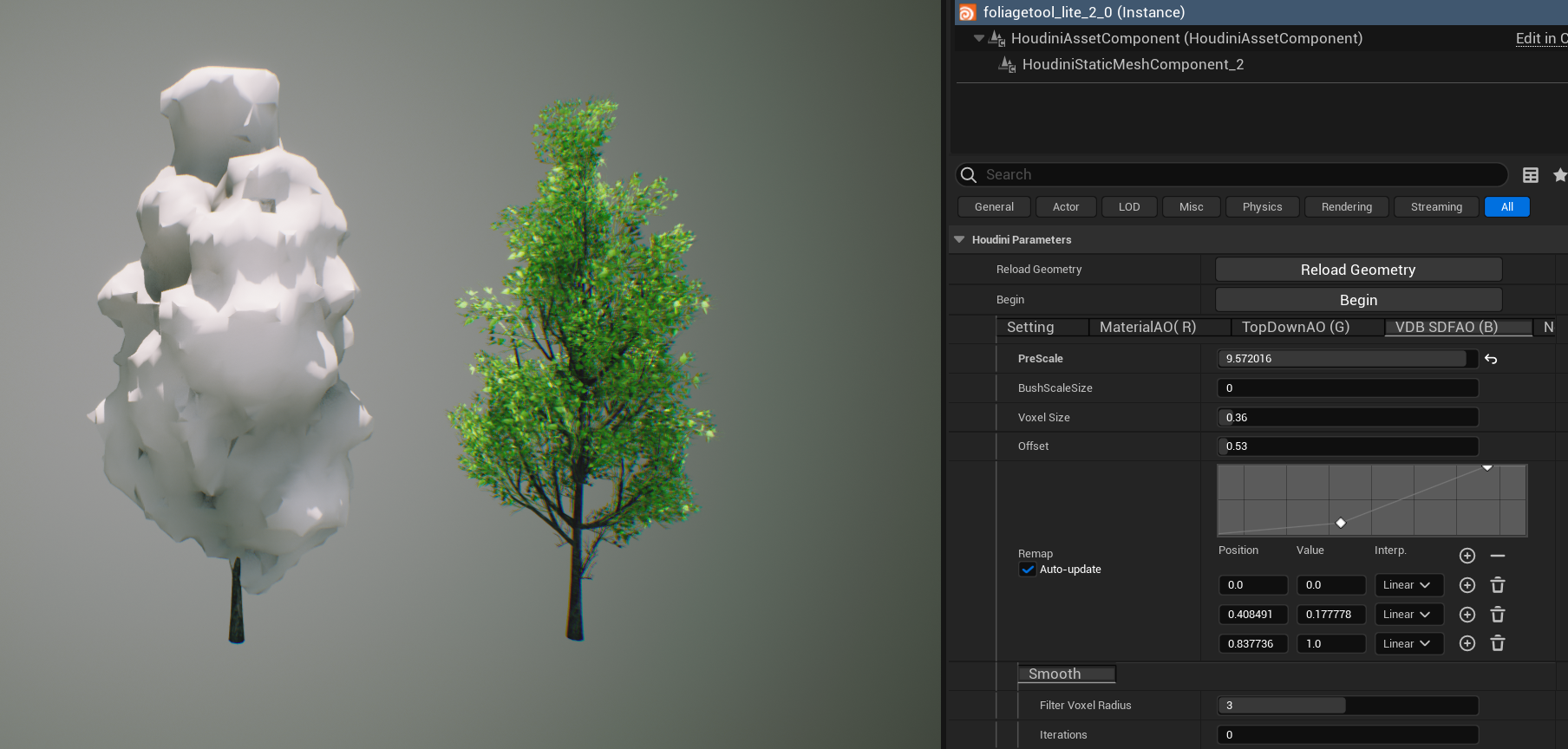
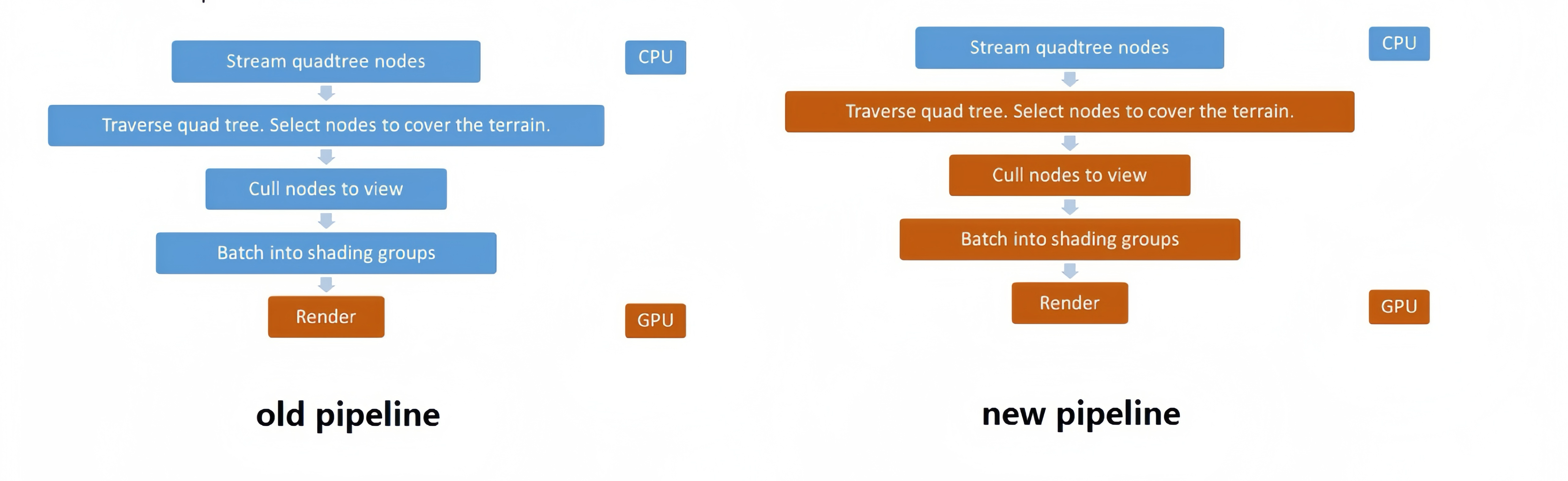
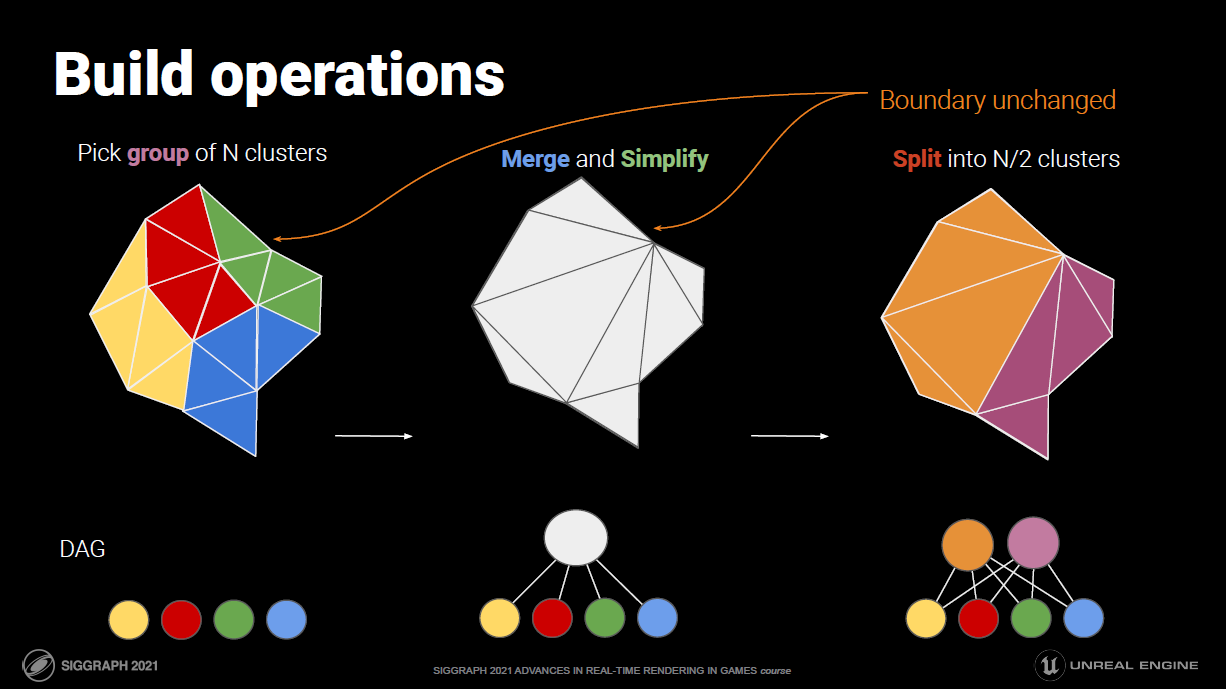
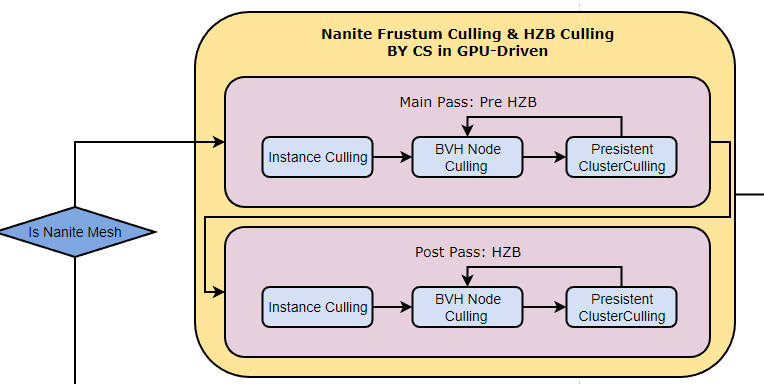
Culling Stage
The Visibility Buffer can achieve storage with fewer index details, typically involving InstanceID, PrimitiveID, MaterialID, and Depth. As it stores index information, its volume is inherently smaller than that of the G-Buffer. However, it requires maintaining a global set of Vertex Attributes and a Material Map. In the Shading stage, the process involves indexing relevant triangle information from the global Vertex Buffer based on InstanceID and PrimitiveID. Pixel-wise information is then interpolated based on barycentric coordinates. Material information is obtained from MaterialID, and together they enter the lighting calculation process to achieve the final shading. This process, to some extent, allows for the separation of geometric and shading calculations, a feat not achievable in traditional Deferred rendering, where G-Buffer serves as the bridge between geometry and shading.
In the Nanite workflow, the format of the Visibility Buffer is R32G32_UNIT, where R’s 0-6 bits store Triangle ID, 7-31 bits store Cluster ID, and G contains 32-bit Depth information. Considering the Deferred architecture of the UE4 era, on the one hand, Nanite currently cannot support all types of rendering, and some meshes still need to be rendered using the traditional rendering pipeline. On the other hand, as mentioned by Karis, a crucial premise of this architectural adjustment is transparency to users. This means that changes in the underlying structure should not impact user-level habits or require relearning the engine, which is crucial. To ensure compatibility between the new and old rendering pipelines, there is an Emit Targets stage to connect Nanite with the traditional deferred rendering approach.
The Emit Targets stage is further divided into EmitDepthTargets and EmitGBuffer phases. Initially, besides the Visibility Buffer, shading requires additional data to blend with hard rasterization data. Nanite employs several full-screen passes to write information outside the Visibility Buffer (such as Velocity, Stencil, Nanite Mask, MaterialID) into a unified buffer, preparing for the subsequent GBuffer reconstruction. Specifically, Emit Scene Depth writes the Depth from the Visibility Buffer into the Scene Depth buffer, Emit Velocity writes into the Velocity Buffer, Emit Scene Stencil writes into the Stencil buffer, and Emit Material Depth writes into the Material ID buffer.
Regarding the MaterialID Buffer, several strategies are employed, depending on the scene’s material complexity. When there are numerous materials, the screen is divided into 64x64 blocks, and the minimum and maximum values of materials in each block are calculated. This calculation is executed by a full-screen Compute Shader, resulting in an image called Material Range. With this image, in the EmitGbuffer phase, a full-screen draw is triggered for each material, where culling is completed in the Vertex Shader (VS) stage. In the Pixel Shader (PS) stage, shading is applied only to corresponding pixels through Depth Compare, thus outputting information such as Albedo into the GBuffer.