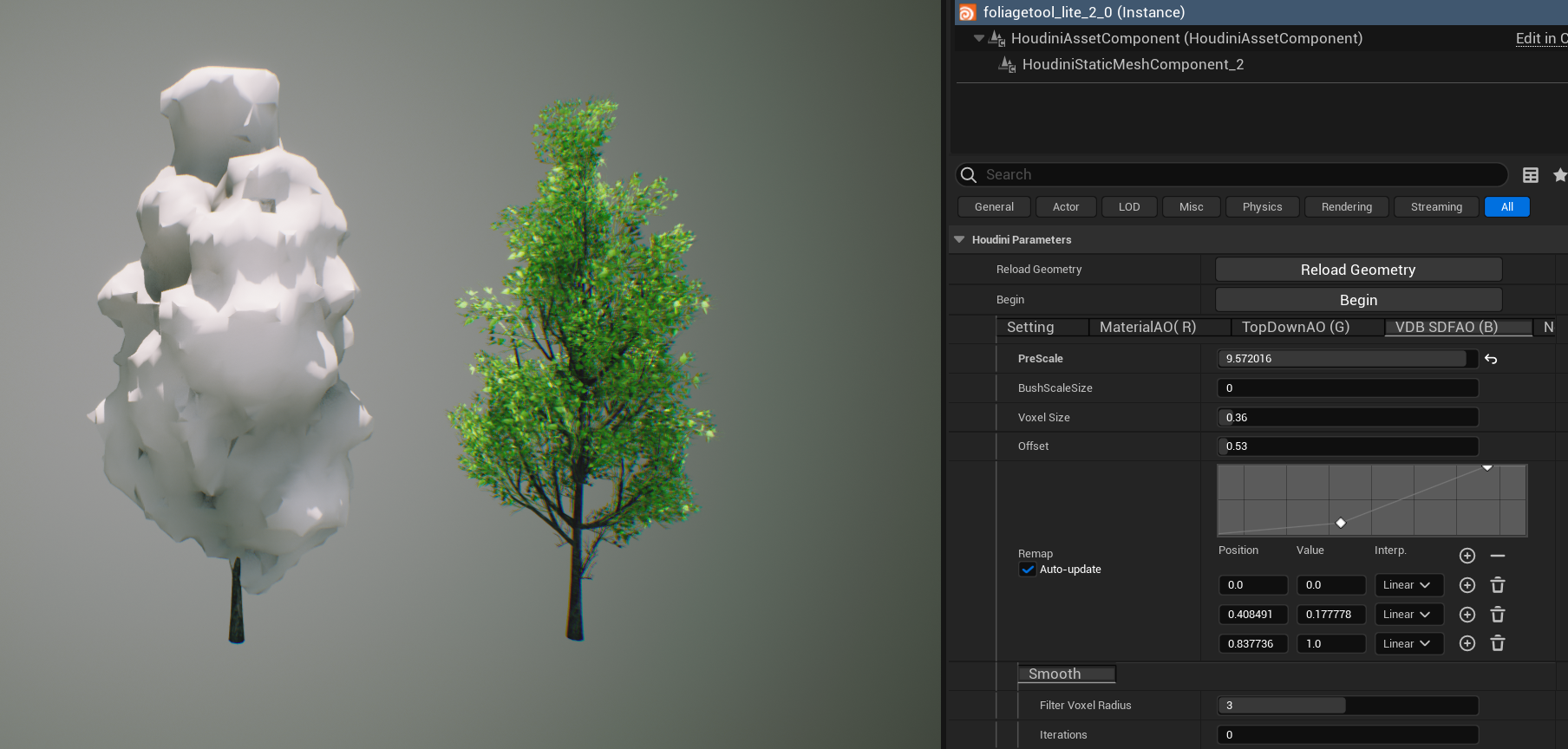
左边是使用了NaniteTreePipeline生成的模型,配合Opaque叶片材质渲染
右边是使用传统手工制作流程的模型,配合Masked材质及叶片遮罩贴图渲染
在都启用Nanite和顶点动画(WorldPositionOffset Animation)的情况下,左边的性能耗时是右边的一半甚至三分之一;并且在右边不启用Nanite情况下的性能耗时相对开启增加了3ms。
这是一个基于流程的自动工具,
旨在将传统的非Nanite植被模型转换为适用于Unreal Engine 5的Nanite模型。

借由项目在2023 UE Fest的演讲上公开相关工程落地细节

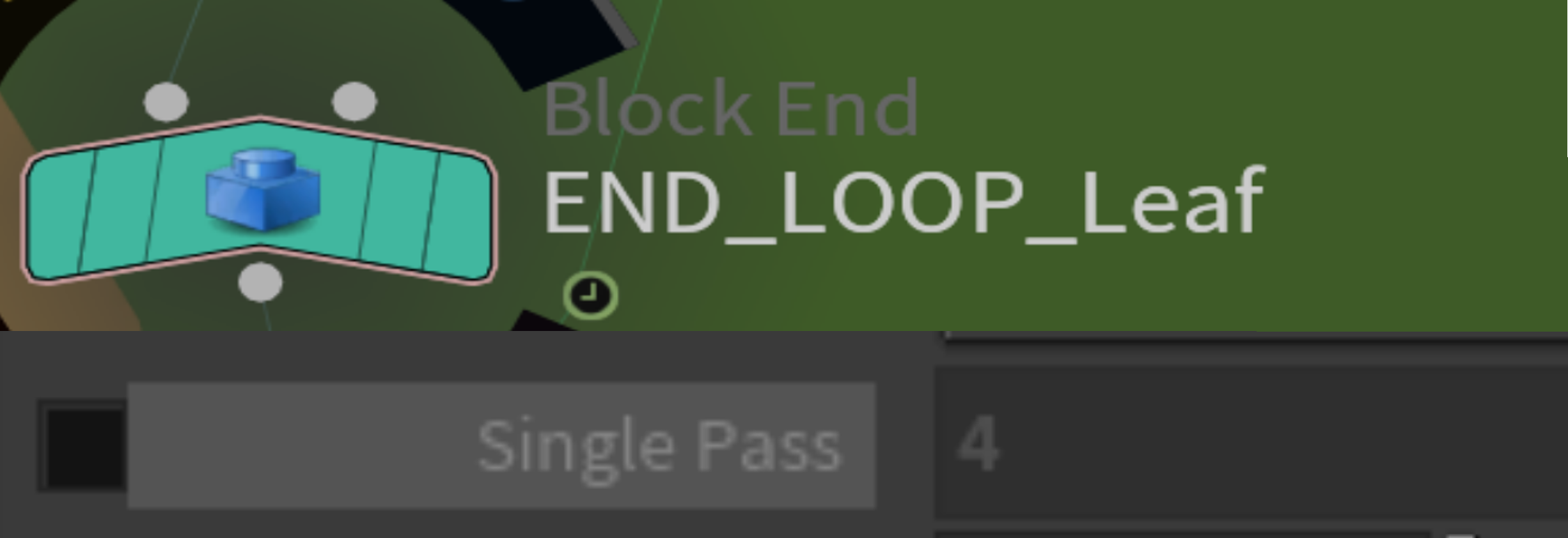
在之前的版本中,输出始终产生错误的叶子。这是由于 [END_LOOP_Leaf] 节点切换了 [single pass],导致循环在单个平面中执行并仅生成一个叶子。因此,所有后续过程都产生了错误的结果。
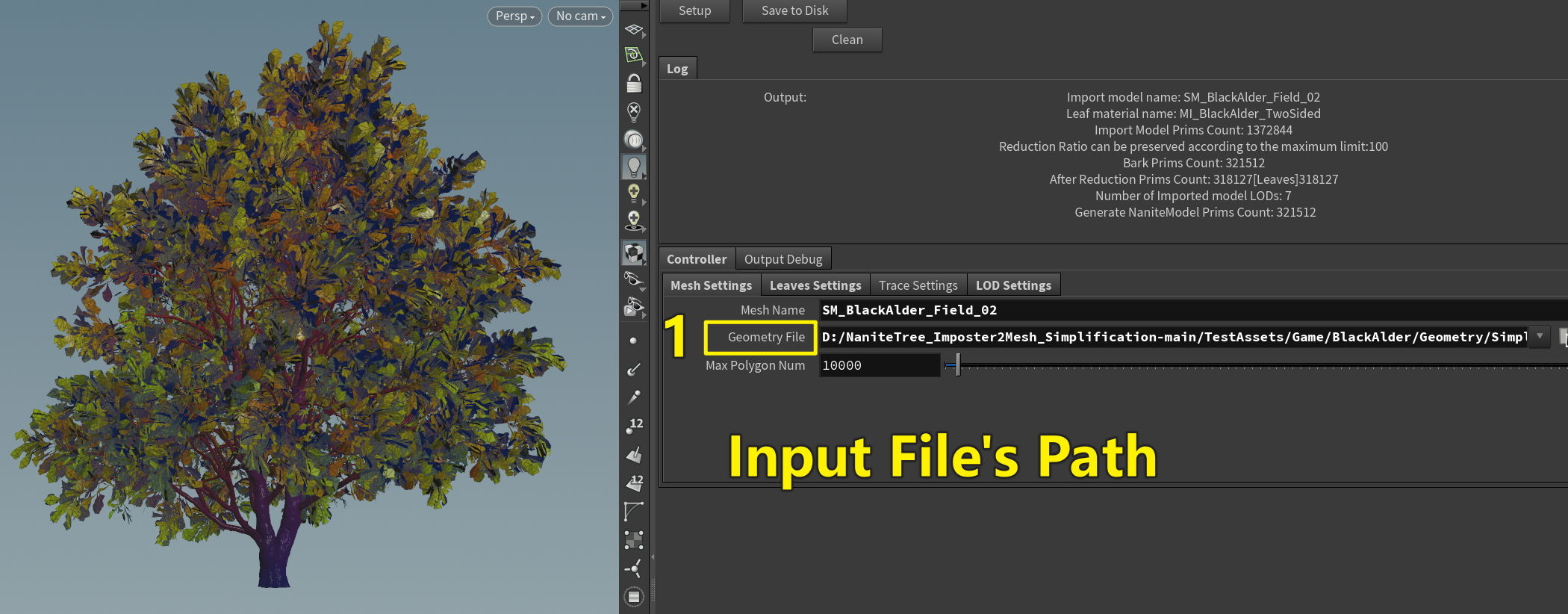
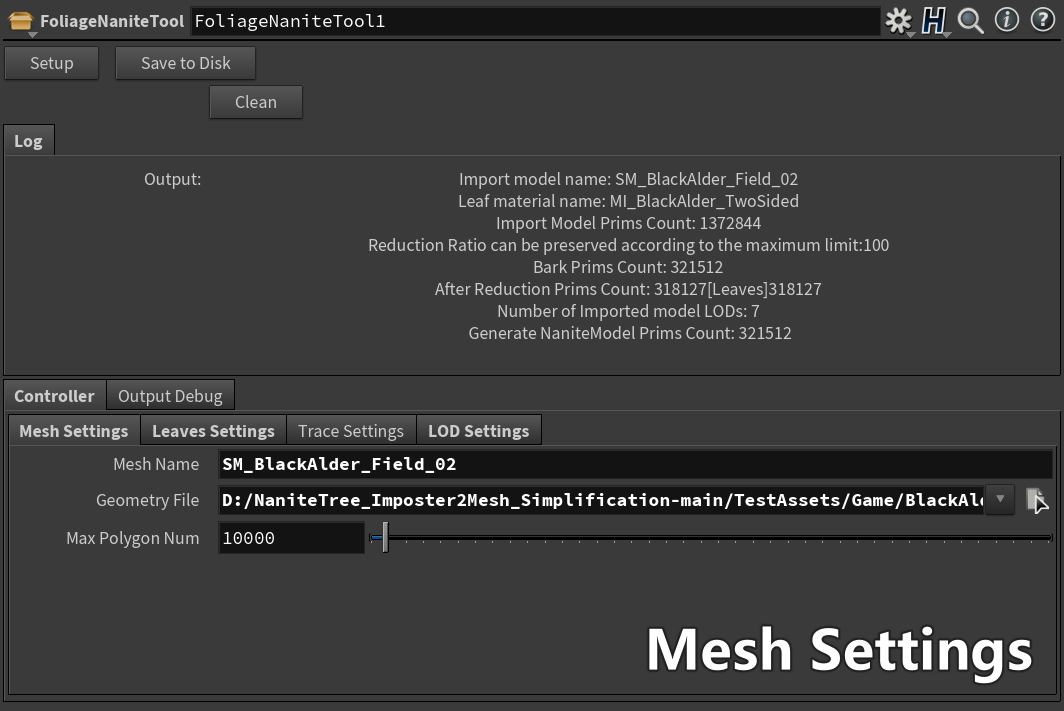
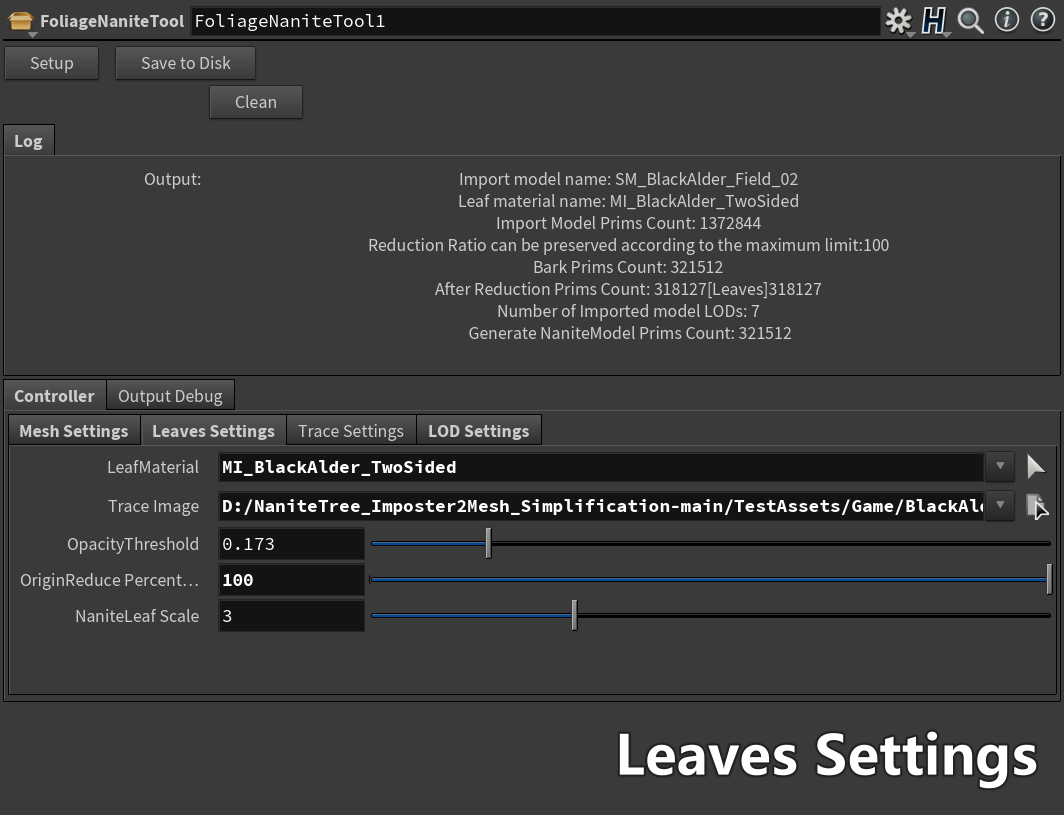
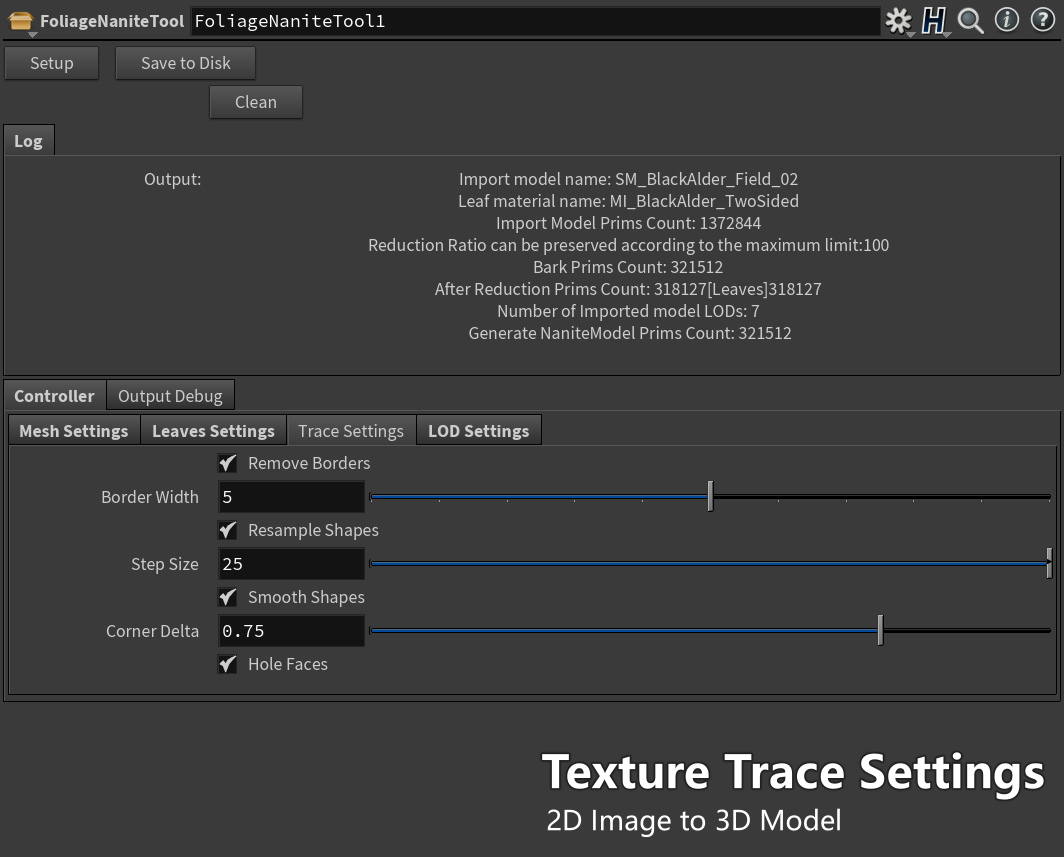
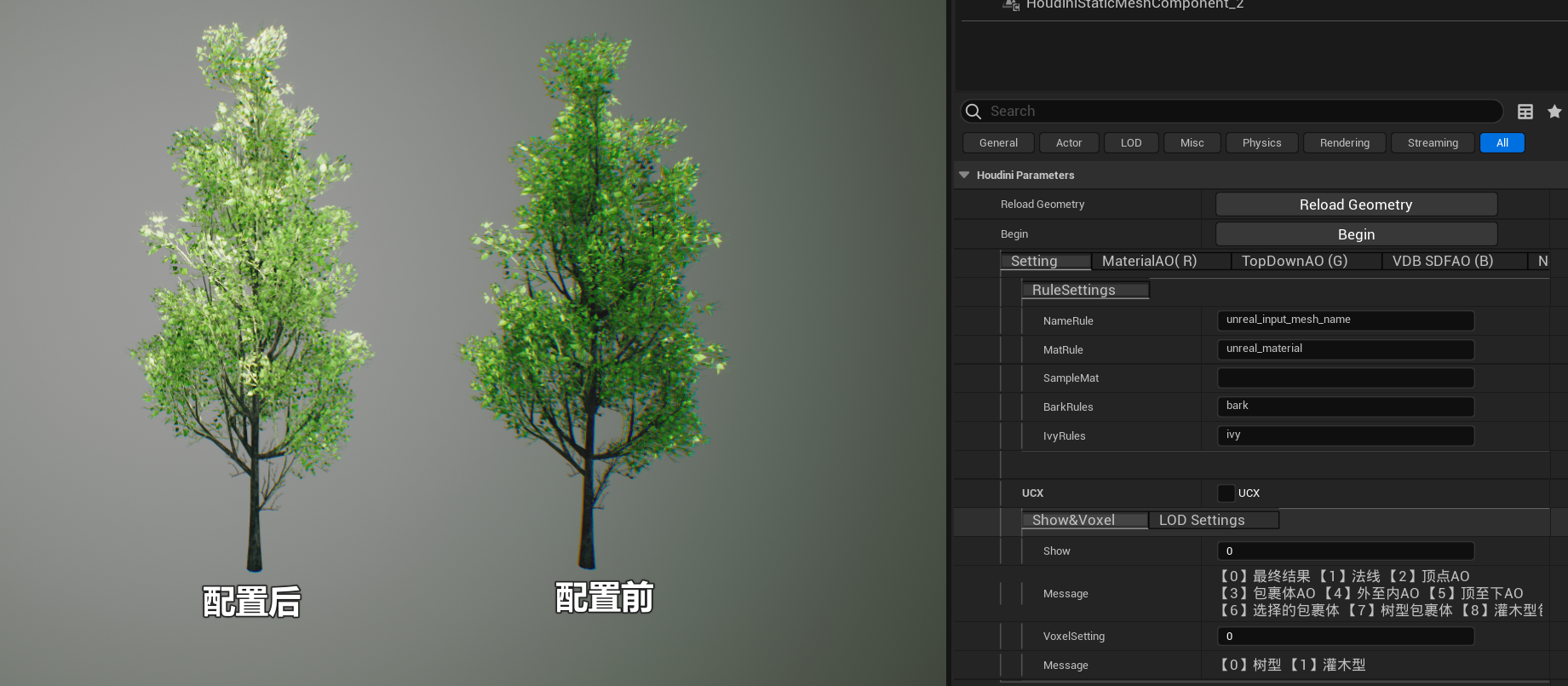
使用时要先确定 输入模型的以下信息 【模型名称 (影响输出的名字】【树干的材质名称】【树叶的材质名称】(这个材质名 是材质插槽名)
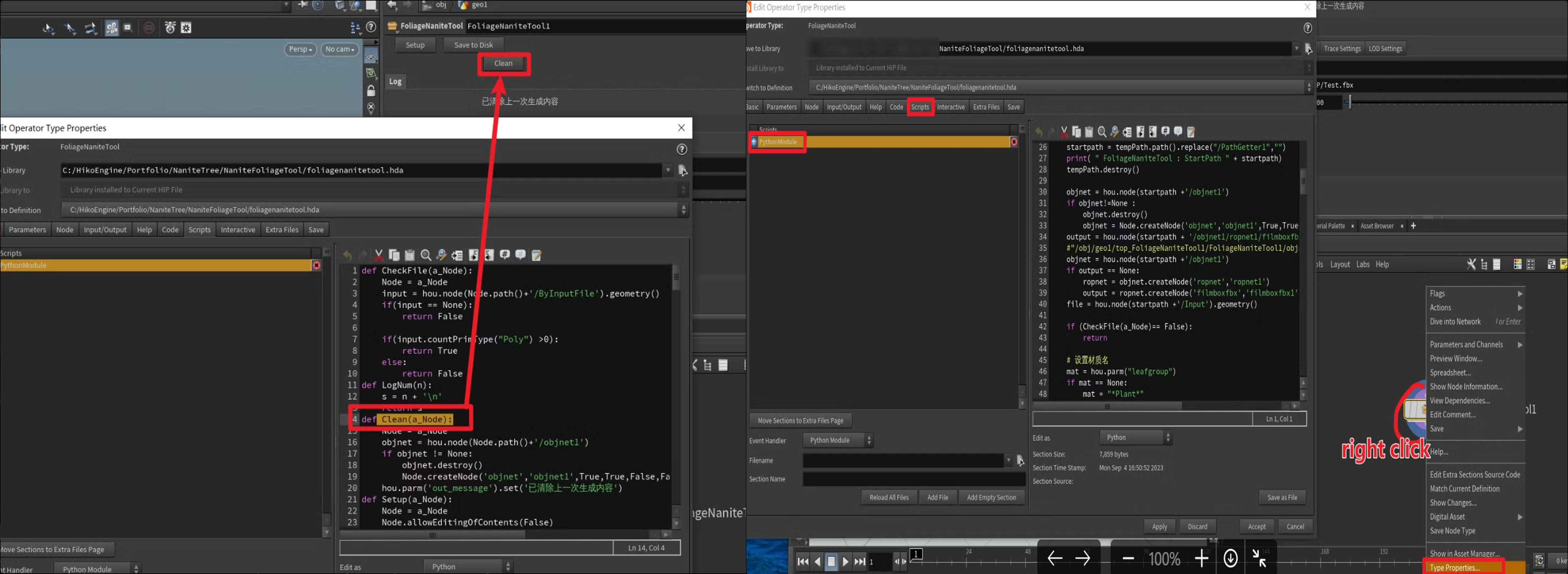
这里可以修改代码 主要是控制按钮
- 有高品质渲染效果追求
- 希望能在传统手工模型基础上提升品质 将项目延展到具有极高品质(如电影画质)
- 想试试nanite的性能和效果

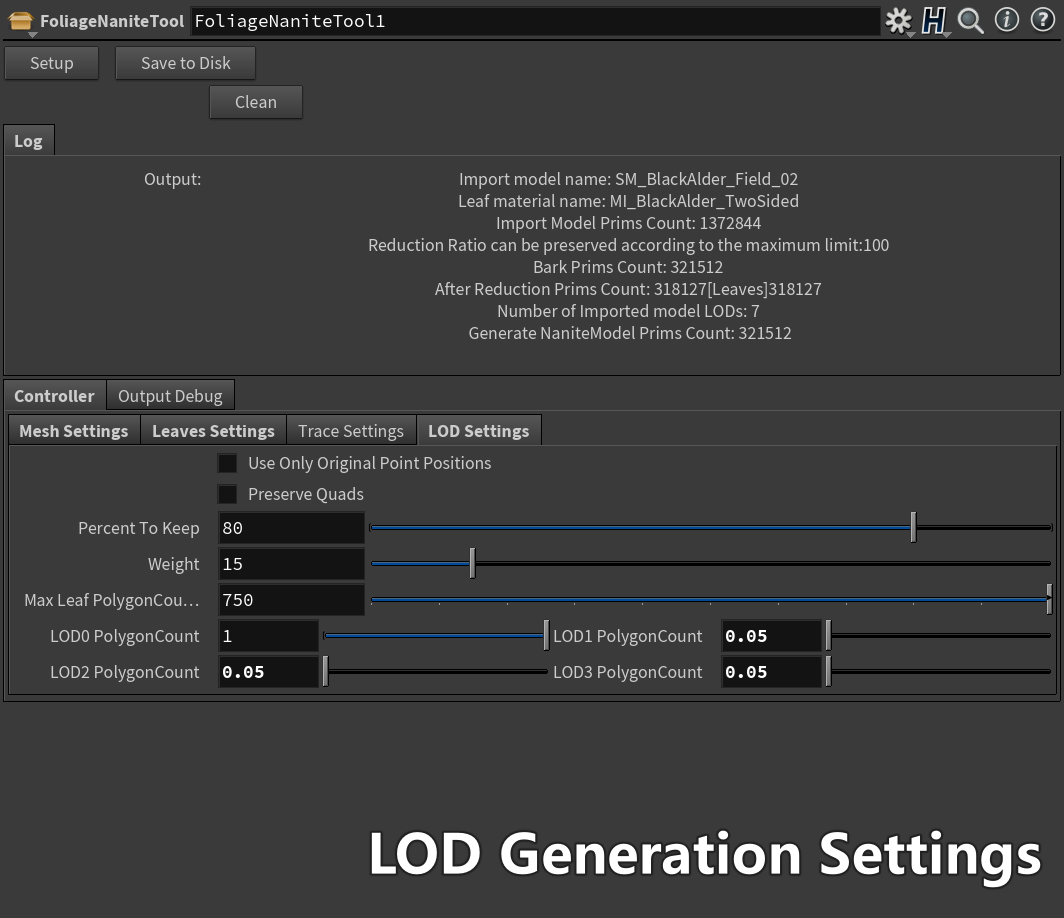
自动识别模型的UCX LOD 叶片部分模型等设置
导出时能够一键根据配置批量设置资产,资产进入引擎后无需二次编辑即可直接使用
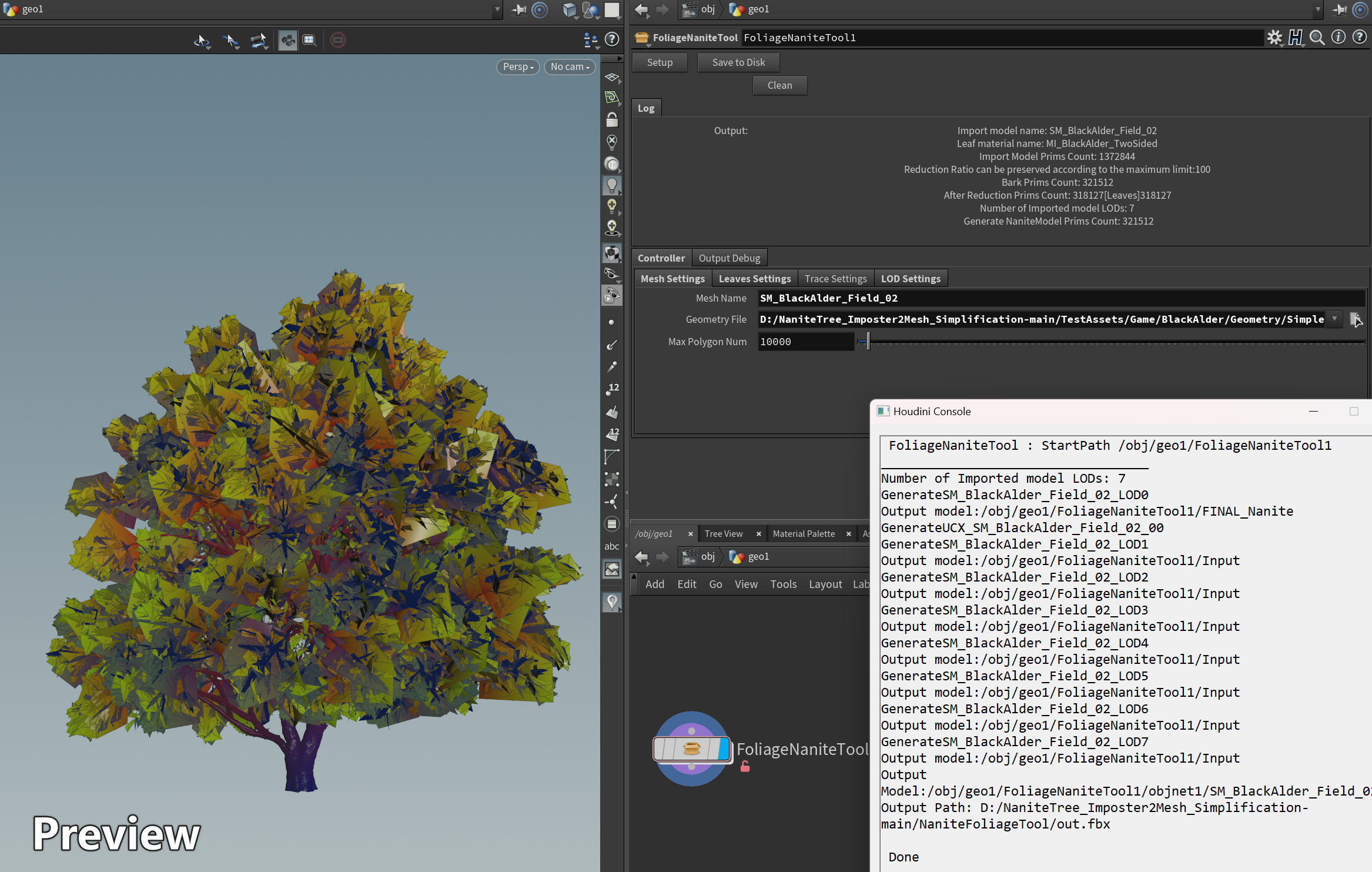
输入模型的路径及其他配置 并点击 Setup (支持按统一配置批量修改)
后续跟进插件路径







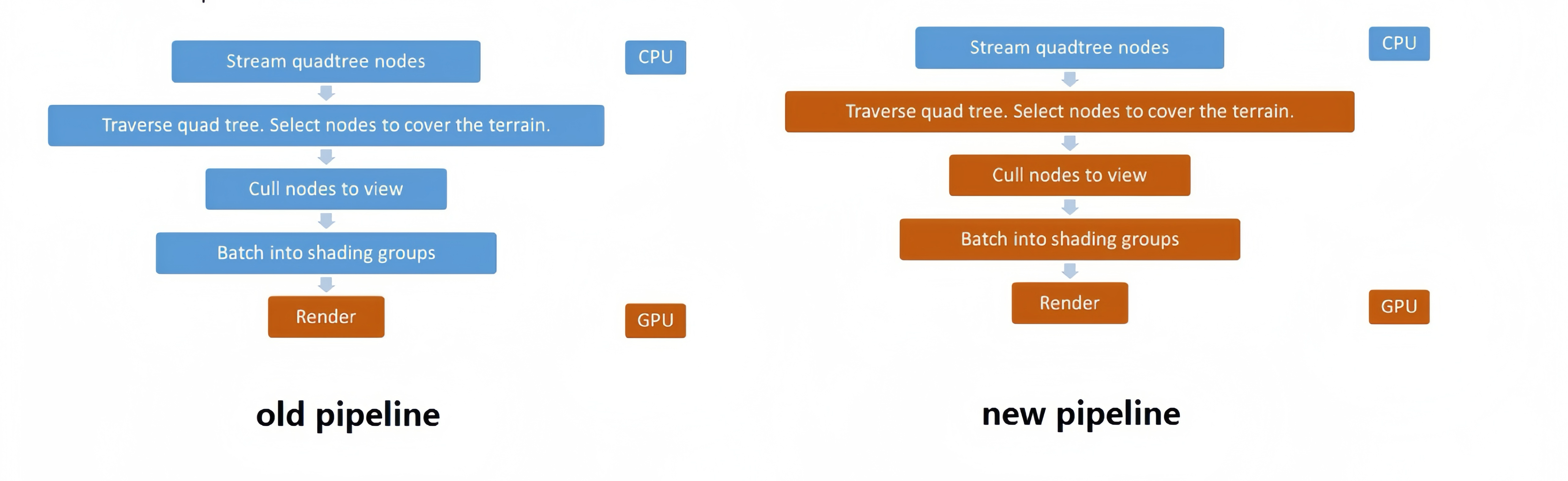
GPU-Driven也是一个老生常谈的话题了,在传统的Vertex - Raster - Pixel Shading流水线式执行过程中,GPU前端【Frond End】在处理完来自Host Interface的指令后Primitive Distrabutor会以Batch为单位将网格信息从Index Buffer 分发给各个GPCs【如果是Nvidia的GPU】,SM单元中PolyMorph Engine承担起了Vertex Fetch,Tessellation,Viewport Transform, Attributes Setup以及Stream Out的功能以连接渲染流水线上下游环节,在Warp scheduler的指挥下线程束完成Vertex计算然后将数据pack到Raster Engine进行硬件光栅化,再被送回SM单元进行Pixel阶段的着色,最后ROP输出。整个过程一气呵成,GPU阶段除了可编程部分我们基本做不了啥,剩下的富逻辑计算与组织部分又是被CPU大包大揽。
一方面CPU的压力越来越大,因此如果GPU能帮CPU分担些渲染之外的计算是再好不过了;另一方面我们又希望能进行比Object或者Instance更进一步的Culling精度。考虑到上述流程的紧凑性,需要在传统渲染管线之外去找这份工作的执行者,目前来看就只剩下Compute Shader了!有了干活的人,接下来还只需要解决一件事,GPU如何自己独立解决计算,判断以及最重要的DrawCall问题。得益于新版本Graphics API的一些特性【Indirect Draw等】可以把部分原本完全由CPU实现的工作交由GPU自身去完成计算与数据读写。这样一方面可以降低GPU-CPU回读的通信延迟,也能充分利用GPU并行运算的能力将剔除粒度进一步细分来降低渲染管线的OverDraw,这就是GPU-Driven的思路。
这方面一些项目颇具工程参考意义,比如SIGGPARH 2015中Ubisoft所分享的《GPU-Driven Rendering Pipelines》,介绍了他们各种基于GPU的剔除手段,包括基于Cluster粒度的剔除,VirtualTexture在整个GPU驱动管线中的支持,并提出了一个非常有意思的概念——“Single Draw Call Rendering“,即一个DrawCall绘制整个场景,虽然有些理想化但整体效能确实提高了很多。紧接着在2016年的GDC中,EA的寒霜引擎给出了他们的GPU-Driven解决方案《Optimizition the Graphics Pipeline with Compute》[2]。2018与2019年的GDC中 Ubisoft又分别给出了基于GPU Driven的地形渲染方案《Terrian Rendering in "Far Cry 5"》[3] 和《GPU Driven Rendering and Virtual Textureing in "Trials Rising"》[4]。UE4也在比较早的版本中设计了自家的GPU-Driven方案,如今这些技术上的沉底全部被用来作为Nanite的框架,也就是说整个Nanite就是基于GPU-Driven而实现的。

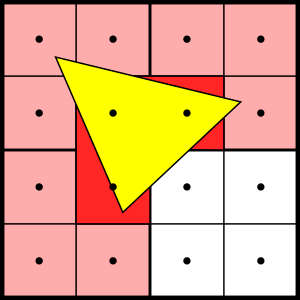
Nanite是混合光栅化策略,至于为什么这么做其实本质还是什么时候使用硬件光栅化合适,什么时候用软光栅合适的问题。 硬件光栅化一般包括两个步骤,以8X8个像素为单位的Choarse Raster和以2X2个像素为单位的Fine Raster。在粗光栅阶段通过一个低分辨率的Z-Buffer将哪些被挡住的Block整块剔除,剩下的就是用于着色的范围,然后Fine Raster以2X2个像素为单位【与一个Pixel Quad】进行最终的光栅化输出【因为我们需要拿到邻近像素的信息来执行DDX,DDY以完成硬件层的MIP计算,所以光栅化单元被设计为2X2个像素而不是单一像素】。硬件这样设计有其历史原因,早期大多数三角面都是远大于一个像素的,相比较于大量Vertex Attributes的Fetch,Texture Sampler以及非常多的Shading计算,硬件光栅化在整个渲染管线消耗中占比非常少,并且在应对大多数场景时效率确实比软光栅要高。 但这种”打多数情况“在偶尔将带来非常严重的浪费,那就是视图中物体面数非常高,三角形非常密集,当小于一个像素的三角形占多数时,Choarse Raster的粗筛基本是徒劳的,而Fine Raster将面临着大量的浪费。比如一个小三角形占据了三个Pixel Quad,而它原本真实覆盖面积可能只有3个Pixel,但2X2的Quad机制会使得12个Pixel都将进入下一环节的计算,这还只是形状比较正常的三角面。对于这种情况,软光栅反而更高效一些。再加上GPU-Driven的加持,可以进行Cluster或者Meshlet层次的剔除,将参与光栅化的三角形范围进一步缩小。最重要的是,整套系统都能在一个流程下衔接起来。
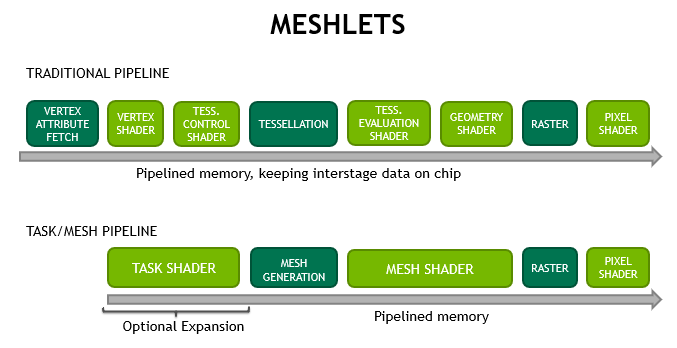
Nvidia在SIGGRAPH 2019上公布了自家Mesh Shader管线[5], 直接一步到位将GPU-Driven干到了硬件层面。因为传统CS里自嗨的GPU-Driven存在一定概率”低效“的风险,究其原因还是与历史的包袱——光栅化管线的执行流程有关。如果不考虑VT这些东西,GPU-Driven解决的主要还是Culling问题,如果一个目标三角形最终被剔除了还好,如果没有则意味着饶了一大圈数据暂存,计算,写入寄存器再回读的过程,因为如果不考虑软光栅,三角形终究要走回原来的渲染流水线,再经历一次Vertex Fetch的过程,而在Vertex Fetch之前还有Primitive Distributor等固定管线没办法绕开。Nvidia的解决方案就是直接把原来的VS, TESSLESION, Geometry全扬了,另起炉灶,让经过协作线程组计算剔除后的MeshLet直接对接硬件光栅器
这样Task Shader本质上就代替了CS去做剔除,MeshShader本身又能承担起几何拓扑的工作。但我们现在知道Nanite并不是Mesh Shader,问题是Why? 这里猜测一是Mesh Shader本身并没有直接解决海量小三角形的问题,另一方面是现阶段使用Mesh Shader的用户硬件成本还很高,不能很好的推广。所以使用了保守一些的基于CS的GPU-Driven与混合光栅化方案,何况按照官方说法,Nanite的创新在于LOD构建与Culling上,这两点本来就是近十年各大游戏厂商”炫技“的舞台。
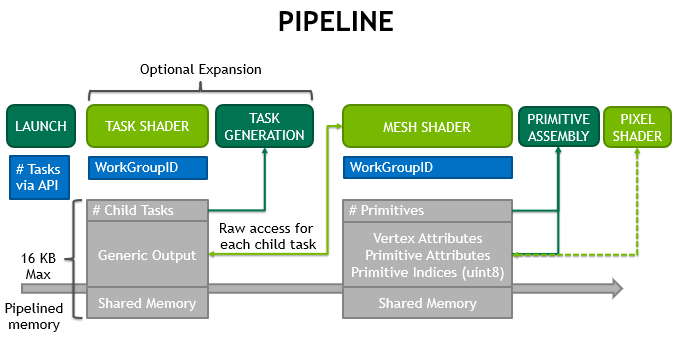
目前分析Nanite的文章不是很多,官方资料主要参考Brian Karis在SIGRPPAH 2021年的分享《Nanite A Deep Dive》[6],以及王祢的《虚幻引擎5的开发路线图及技术解析》[7],非官方方面技术分享写的不错的主要是这四篇:[8],[9],[10],[11],另外结合最新的5.0.3源码进行分析。 Nanite的整套实现机制涉及非常多方案的工程积累,GPU-Driven,软光栅,几何建模与BMT处理,还有数据压缩。难能可贵的是把这么多东西全部堆入原本就如此庞大的Deferred渲染架构,还能保证运行足够快和上层设计流程的透明【底层架构的改动不会影响到上层用户原本的操作方式与开发流程】,这不仅需要丰富的图形开发知识,炉火纯青的引擎工程能力,更需要巨大的勇气,甚至一点丧心病狂的精神。 要实现这个目标听起来有点离谱,不过毕竟是Brian Karis,倒也正常。 宏换上来看,整个Nanite的渲染管线步骤如右图:

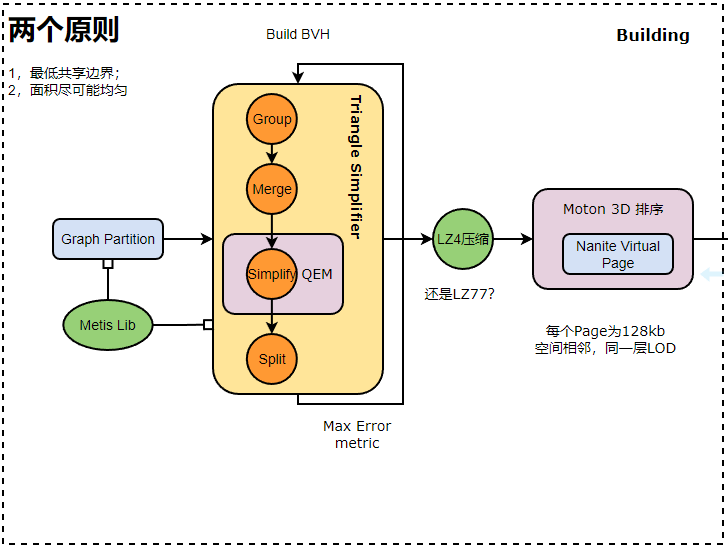
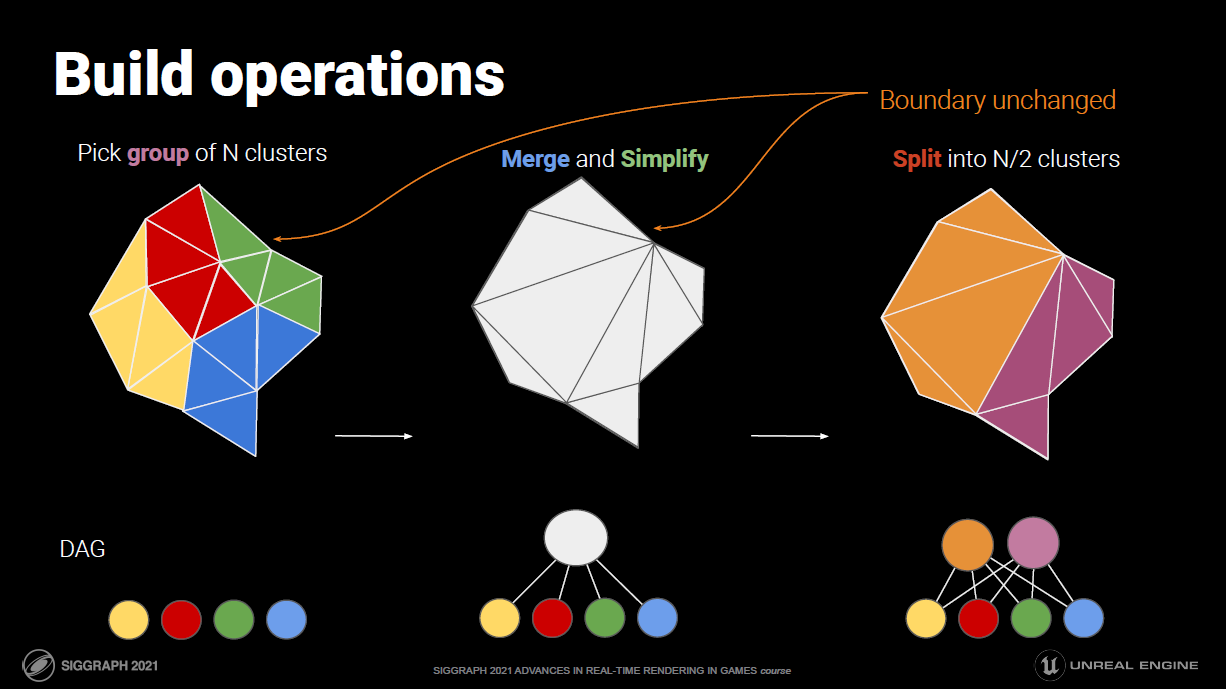
首先是生成Nanite Mesh阶段,也就是Graph Partition,流程如右图:将整个Mesh切分成128个三角形一组的Cluster,Cluster与Cluster之间遵循“最低贡献边界”与“面积尽可能均匀”的切分策略,这样能够保证后面减面过程误差尽可能小。构建LOD时候的逻辑是这样的:首先32~64个Cluster会组成一个Cluster Group;Cluster Group会进行一个Lock Edge操作,这部分非常重要,是保证良好质量切分的基础。然后对Group内部的三角形进行Merge,这一步过程会逐渐去掉内部边界,但不会影响Group边界,有个专门的三角形简化器做这个,减面算法使用QEM【二次误差度量】;这样就得到了LOD1级的Cluster Group,然后再对LOD1级的Cluster Group内部执行Split,重新切分三角形.
从右边的简化图【每个Cluster以4个三角面替代作为示意】可以看出,减面后重新生成的三角形边界与形状其实与LOD级的三角形已经没有关系了,减面过程并不是粗暴的”二合一“或者”多合一“;但同时整个Group的外边界是被lock住的;减面过遵循”最低贡献边界“与”面积尽可能均匀“的策略保证了每一次减面”三角形带“之间的面积比例与覆盖形状都不会偏差太大,这能带来更低的投影误差和更高的切图精度。
每一次迭代都会依据上述原则进行,每一次Group,Merge,Simplify,Split生成新的LOD都会记录Cluster误差与Group误差,然后与下一次生成误差做max拿到一个新的Max Error Metric,这样整个LOD树的误差随着面数升高一定是降序排列的,这使得后面依据屏幕投影占比与误差比较以选择合适的LOD层级成为了可能。迭代器会生成一个树形结构,根节点只有一Cluster,然后以此构建BVH,为后面GPU-Driven的Culling做加速准备,整个过程都是并行化完成的。
BVH构建完毕后,以Cluster Group为单位建立分页的数据存储模型,每个page为128kb,一个限制条件是只有空间相邻,且处于同一个LOD的Cluster Group才会被放到同一个Page,为了保证空间邻近与数据编排连续性,使用”Morton 3D“。另外,能够看到的是Nanite Mesh所持有的顶点信息是非常少的,甚至没有Vertex Tangent数据,Tangent数据是根据已有的点属性实时插值算出来的,两个原则一是能算出来的就干掉以节省存储,IO压力与索引计算,二是尽可能减少必须属性的占位位数。
Nanite Mesh构建过程完毕后有一个非常重要的步骤就是数据压缩,因为顶点数非常多,后续计算又要保证有一个全局的Vertex Buffer,为了高效即时的串流操作必须对数据进行压缩,具体的压缩算法还有待考究,不过这是一个在精度损失与性能之间折中的过程,Epic肯定是找到了最佳权衡点。
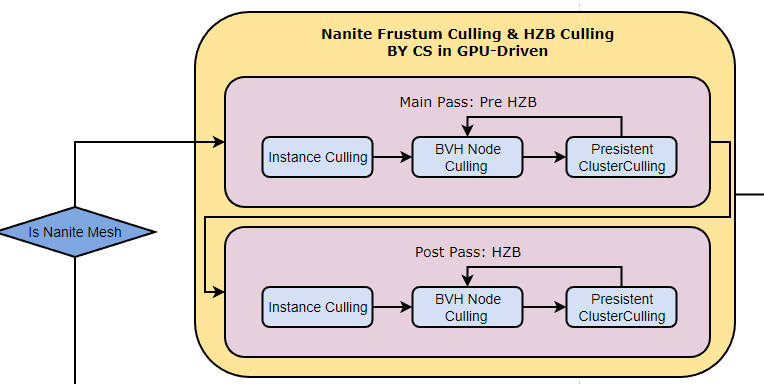
Culling,整个过程都是GPU-Driven的,这里的执行的视锥剔除与HZB剔除,Back Culling与小三角形剔除并不在这个环节完成。一共三级,首先是Instance层面,也就是传统渲染管线所能实现的剔除粒度;然后通过Instance剔除的Mesh会进行BVH Node Culling,这个过程是层次式,动态的。这里有个问题是怎么保证CS线程组的负载均衡,也就是如何分配线程组使得每个线程都会被充分利用,而不是闲置等待中。因为每个Mesh的BVH深度可能差别很大,所以Node Culling阶段以Cluster叶节点为粒度去分配线程组肯定是不合适的,UE5这里的做法是维护一个全局的FIFO队列去取BVH节点,如果该节点通过了剔除,就把该节点下的所有子节点全部转移到队尾,然后继续循环全局队列中取新的节点,这个过程一直到队列为空为止。通过这样的模式,Nanite就保证了各个线程之间的处理时长大致相同;通过的节点会进一步的进行Cluster层级的剔除,经过三级剔除,保留下来的三角面相比较传统管线浪费率已经大大降低。
具体的剔除实现可以参考NaniteInstanceCulling.usf与NaniteClusterCulling.usf两个文件,需要重点关注的函数有DrwImposter,IsPrimitiveShown, InstanceCull,CompactViewsVSM_CS,InstanceCullVSM,GetProjectedEdgeScales,ShouldVisitChild,SmallEnoughToDraw,NodeCull,ClusterCull,ProcessClusterBatch,PresistentClusterCull, WriteRasterizerArgsSWHW, InitClusterBatches,一行行的看因为每一个函数都很关键,算法实现代码编排也清晰,而且基本上个各个功能的作用是什么看名字就能看出来。这么清晰的代码在Unreal里实属少见,如果经常阅读源码大概有体会,就质量和风格而言,虚幻里只有两种代码,一种是Brian Karis的代码,一种是其他程序的代码。
实际上整个剔除分为两个Pass进行: Main Pass和Post Pass,从图上看这两个Pass的逻辑基本一致,区别在于Main Pass的遮挡剔除是基于上一帧的数据,而Post Pass即使用Main Pass结束后构建的当前帧HZB,两道Pass主要是为了提高剔除的准确率。另外Cluster剔除阶段会标记该三角形是走软光栅还是执行硬件光栅化,这取决于它们的尺寸。
前面通过GPU-Driven的Culling,数据压缩与混合光栅化解决了OverDraw,通信等待,数据串流与海量小三角形绘制的压力,到了Shading阶段还有大量材质导致的GBuffer膨胀问题,在UE4的时候PC端使用了7RT的G-Buffer方案,并对可支持的光源特性与材质类型上限做了限制【ShadingModelID】,到了UE5面临着更多的微形三角面,更高分辨率表现的需要,为了进一步降低读写带宽压力,Unreal引入了一种在目前工程实现上仍算比较激进的方案-Visibility Buffer。这玩意其实早就被提出来用于解决延迟渲染的GBuffer膨胀问题,但目前来看真正实装的引擎其实很少,有产品验证的更是寥寥无几。
Visibilty Buffer可以做到存储有占用更少的索引信息,一般是InstanceID, PrimitiveID,MaterialID这些,还有Depth。由于存储的是索引信息它的体量本身就比G-Buffer要小,但需要维护一个全局的Vertex Atributes与Material Map。这样在Shading阶段只需要根据InstanceID与PrimitiveID从全局的Vertex Buffer中索引到相关三角形信息,然后依据重心坐标插值得到逐像素信息;从MaterialID获取对应的材质信息,并一起进入光照计算流程完成最终着色。这个过程一定程度上可以做到几何计算,着色两个环节的解耦,这是原本以G-Buffer作为几何-着色桥接的Deferred所无法实现的。
在Nanite流程下Visibility Buffer格式为R32G32_UNIT,R的0~6bit存储Triangle ID,7-31 bit存储Cluster ID,G为32 bit的Depth信息。考虑到UE4时代的Deferred架构,一方面目前Nanite无法支持所有类型渲染,一部分Mesh还是要用传统的渲染管线完成绘制;另一方面,就像Karis所说的,这次架构调整一个重要的前提就是必须对用户透明,也就是底层的改动不会影响到用户层面的操作习惯,也不需要重新学习引擎,这是很重要的。为了兼容新旧两套管线有一个Emit Targets的环节去连接Nanite与传统的延迟渲染。
Emit Targets又分为EmitDepthTargets与EmitGBuffer两个阶段。首先,除了Visibility Buffer,Shading还需要一些额外的数据, 为了与硬光栅的数据混合,Nanite有几个全屏的Pass将Visibilty Buffer之外的信息【如Velocity,Stencil,Nanite Mask,MaterialID】一起写入统一的Buffer中,为后续重建GBuffer做准备。即通过Emit Scene Depth将Visibility Buffer中的Depth写入Scene Depth,通过Emit Velocity写入Velocity Buffer,通过Emit Scene Stencil写入Stencil,通过Emit Material Depth写入Material ID。
特别的对于MaterialID Buffer,区分除了几种策略,具体与场景的材质复杂度有关。当场景的材质数目非常多时,会将屏幕分割成64X64的Block,统计每一个Block中材质的MIn&Max值,统计由一个全屏的CS执行,结果会得一张被称为Material Range的图,有了这张图EmitGbuffer环节每一种材质启动一次全屏绘制并在其VS阶段完成剔除,在PS阶段则通过Depth Compare只针对对应的Pixel进行Shading从而输出GBuferr中的Albedo等信息。


There's a lot of excellent work that was introduced for Nanite Tree Simplification.
Lindstrom-Turk Cost and Placement Strategy introduces edge collapse operation for triangle Simplification.
Garland-Heckbert Cost and Placement Strategy based on iterative edge contraction and quadric error metrics.
Cost Strategy Policies is selected through three strategies: GetPlacement, GetCost and Filter.
SIGGRAPH 2015 ubisoft, GPU-Driven Rendering Pipelines [1],
GDC 2018 Ubisoft, Terrian Rendering in "Far Cry 5"
GDC 2019 Ubisoft, GPU Driven Rendering and Virtual Textureing in "Trials Rising"
Based on Turing architecture GPU Mesh Shader
SIGGRAPH 2021 Epic Games Brian Karis Nanite A Deep Dive
Mi Wang Unreal Engine 5 development roadmap and technical analysis
Jiff UE5 Nanite Brief analysis of implementation
Cheng Luo Introduction to UE Rendering Technology: Nanite
Yue Cong UE5 Nanite source code analysis for rendering: Rasterization
Wang Xiang UE5 Special Part 1: Nanite
@article{nanitetree,
author = {jiayaozhang,Hikohuang},
title = {Nanite Tree Pipeline},
year = {2023},
}